

One of the unique, but not well discussed design distinctions of the Aion Virtual Machine (when compared to most other blockchain VMs) is its storage model. Whenever I say “hybrid storage model”, all of the eyes in the room quickly glaze over with either confusion or disinterest.
Here, I want to explain what this means and why it will be game-changing for how smart contracts are developed.
Virtualizing what?
Let’s take a step back and first talk about what puts the “virtual” into “virtual machine”. While there are lots of answers to this for different VMs (usually around virtualizing a different architecture, full machine without one, or ideal machine), we want to focus on blockchain VMs.
In this environment, what we really want to virtualize is: A program starts and then runs forever. After all, it “starts” when it is deployed, and then can respond to events as though it was always running, until it is deleted. The space between that start-stop could last for years and the program would act as though it never stopped.
But it clearly does stop. All machines the program is running on probably stopped several times. So how do we provide this virtual behaviour, the un-provable lie that the program never actually stopped? Storage.
Confused? Well, consider the program thinking “I am going to store some information into this variable and come get it later… oh wait.” This means that the program needs to store this data somewhere persistent. One of the key differences between blockchain environments is how that persistent storage is exposed.
Storage in Blockchains
Key-value Store
In Ethereum’s EVM, the storage abstraction is a key-value store. However, Solidity does a good job of making this seem transparent. It does this by being designed around this limitation. If the language can only describe what can be mapped to a key-value store, problem solved!
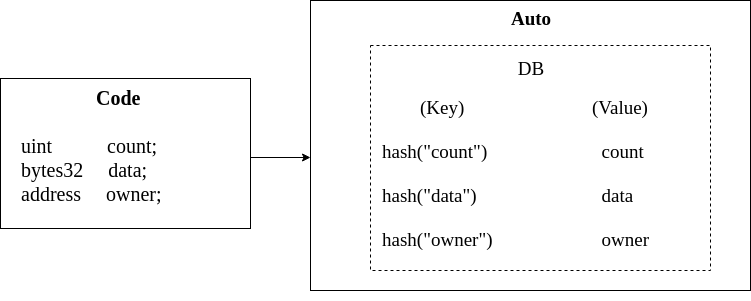
However, this only works if the high-level language has this shape, and it has the downside of needing to do lots of small IO operations. When it comes to optimizing storage access, the number of accesses usually hurts more than their sizes.
Manual Storage
Other projects which use more general-purpose languages typically make this a manual responsibility of the developer. While this gives them control and is generally not too cumbersome (many developers are used to the idea of business logic and persistence being distinct), it forces the developer to do this work which also means that the VM can’t optimize it.

Object Graphs
What if we could just decide what data the user would need in the future, at the VM level? In that case, we could dynamically manage the storage for them, with arbitrary data topologies (not the flat structure Solidity uses to statically solve this problem).
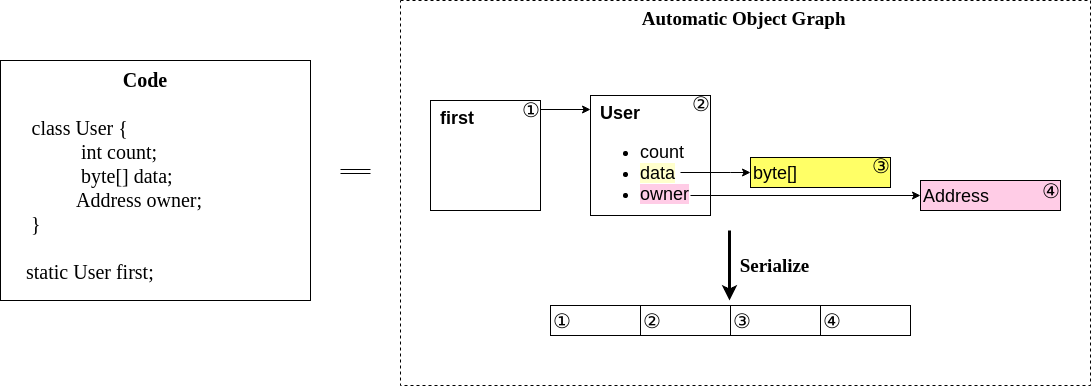
Not only could we do this transparently, but we could also optimize it at the VM level: “you always use these objects together, so I will store them together”.
This kind of physical locality concern is the basis of optimizations in any environment where moving to a new read/write location is of high cost. While this applies to physical disks, it also applies to memory, where it is the basis of managed heaps (think Java or JavaScript memory — you don’t directly access the memory, just the objects — this allows the VMs to be clever).
Limitations of Object Graphs
We experimented with this in the AVM but ran into some problems.
First of all, how do you reclaim the orphaned data without reading all of it? This required some notion of garbage collection to be run as part of a special transaction or some other consensus-relevant time, adding a lot of complexity to both the VM and the protocol.
Secondly, how can I build an off-chain application which uses Merkle proofs to verify its on-chain state when the data is stored in such a way? The graph can have any arrangement, so the elements can’t be addressed by something like a key. Furthermore, the graph can contain arbitrary depth or cycles, meaning that there is no way to build something like a Merkle DAG (directed acyclic graph).
AVM Hybrid Storage
The solution we went with was: “why not do both?”
This means that we always run with transparent object graph persistence, but we always operate on the entire graph at once. As a result there is no special question of how to collect orphaned data from the storage. We keep this small by billing for the read/write of the graph on every transaction. If the graph is small, this is far cheaper and faster than issuing several small reads and writes for each transaction (instead, just issuing one larger one for the entire graph).
However, for bulk storage of data which requires off-chain verification, we also expose an API for manually interacting with a key-value store.
For the developer, this means taking advantage of the graph for application state and decision-making, while also leveraging the key-value store for large or per-user data. This also means applications which only have a very small size may have no need for the key-value store at all, as they rely entirely on the automatic management of the graph.
Developers — How to Use the Graph
The object graph persistence is meant to be fully transparent to the developer. Concretely, this means you just write as you would write a normal Java application:
- design to be correct and concise
- write to be understandable
- never pre-allocate
- don’t keep objects around once you are done with them
Beyond that, the illusion of the program which started once and runs forever should be complete:
- write to a static field, see the value in a later transaction
- store the same reference in 2 places, they are instance-equal in a later transaction
- modify an object deep in the graph, see the change persisted in a later transaction
- hold a reachable object while issuing a reentrant call which modifies it, observe the change when the call returns
How the Graph Works
To put it directly: it works exactly like a garbage collector.
In greater detail:
- walk all class statics, adding each object found to a set of discovered objects and, if not already in that set, to a work queue
- remove an object from the queue, scan it, adding each object found to the discovered set and, if not already in that set, to the queue
- continue reading the queue until it is empty
Note that this is a breadth-first traversal of the graph.
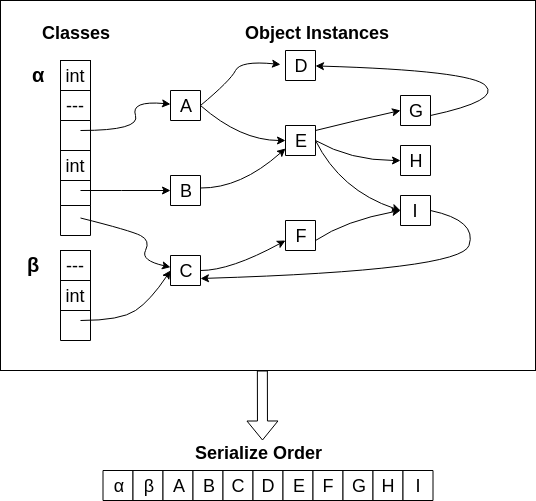
For each object found, it is serialized using an internal serializer defined by our specification. This includes object type, primitive fields, and references to other objects.
Using the breadth-first ordering and our serializer, this allows the creation of an unambiguous serialized binary representation of all the objects reachable at the end of a transaction.
When a transaction starts, these objects are read, instantiated, connected to each other and roots stored back into the class statics.
What about Consensus Hash?
We treat the existing key-value store exactly as it is in FVM (or EVM, for that matter), with the one change being that we allow arbitrarily-sized values. Otherwise, this builds a trie which is used to compute a key-value hash for the entire store, just as before.
The difference is that we also hash the serialized object graph and combine that hash with the root hash of the trie in order to develop our hybrid storage root hash. This is the storage hash used in consensus.

This means that a Merkle proof cannot apply to objects in the graph, but can still be used to prove the state of the key-value store.
Simplify Contracts, Simplify Improvements
There are 2 things which most directly excite us about the object graph in the storage model:
- simplification for developers
- future VM-level improvements
For developers, the object graph allows automatic management of basic contract logic state which would otherwise need to be manually handled by their code. This not only makes the code smaller but also makes it impossible to make mistakes (typically omissions) in any related code path.
This has the side-effect of improving both developer ergonomics but also the correctness of the contracts on the platform.
From the VM perspective, managing the graph requires that it do more work, but also allows for some fascinating optimization opportunities and introspection into contract execution patterns.
Instead of forcing this low-level management onto the user and blinding the VM to the meaning of the program and its data, keeping the user at the high-level and exposing this meaning to the VM makes new directions possible.
Together, this makes the graph a game-changer, in that it makes writing correct contracts easier and improves their overall performance.
